Doug Lea, State University of New York at Oswego
[This is an ongoing expansion of topics discussed in my Coordination 97 conference paper. Comments would be very welcome.]
The design of object-oriented open systems has two principal foci:
The tension between these two facets of design is captured in the OO notion of responsibility [Wirfs-Brock]. To quote Kent Beck [Beck]:
If we're always programming from the outside, how do we ever get anything done? I definitely change gears between "what services does this object provide?" or "how do these services divide between these objects?" to "how am I going to accomplish that?", sometimes several times a minute (sometimes days go by).
These concerns apply even to in-the-small OO programming. But they become accentuated in the development of open systems, in particular those developed in Javatm. The Java programming language was created in part as platform for open, distributed, reactive, concurrent applications. Java-based components, frameworks, infrastructures, and systems are currently being rapidly developed and deployed. This paper explores some occasionally disguised aspects of responsibility-driven design seen in the development of Java-based open systems.
Activities running on open systems demand a certain quality of service that increasingly requires that the associated objects support features or aspects [Kiczales] that improve the reliability, performance, generality, and reusability of their functionality. An expansive view of such ``nonfunctional requirement'' or ``quality factor'' support includes:
| Concurrency control | Protocol negotiation | Bandwidth negotiation | UI look and feel |
| Access Control | Authentication | Versioning | Indexing |
| Persistence | Memory management | Serialization | Storage layout |
| Administration | Accounting | Auditing | Mobility |
| Replication | Transport | Parallelism | Activation |
| Resource control | Flow control | Scheduling | Prioritization |
| Bidding | Input Media selection | Platform adjustment | Payment |
| Media synchronization | Load balancing | Buffering/Caching | Encryption |
The presence, nature and control of such features differ from those of the basic services provided by higher-level objects. Typically, quality features are not considered to be part of the interface describing the services provided by application objects (thus differ from application-level features [Prehofer,Zave]), or even of their abstract semantics (although this varies in degree across services and applications), but instead control the ways in which operations are carried out.
In many cases, the development of code dealing with such infrastructure issues represents the majority of effort in supporting an object's desired functionality. However, application-level objects generally do not perform these duties all by themselves, but instead obtain them with the help of ``back office'' infrastructure components.
The main division of responsibility is for infrastructure objects to supply basic mechanism, and for higher level objects to select the policies governing their use. The infrastructure components that help provide adequate quality of service represent a loosely coupled extensible microkernel-style [Tanenbaum] computational substrate in which application-level objects choose only those combinations of services that they actually require.
Ideally, this common general architecture enables activities across application-level objects to be scripted using relatively simple protocols, for example those based on push or pull flow, blackboards, etc [Lea,Shaw,Buschmann]. At yet coarser levels of granularity, these may in turn be treated as services.
One strategy for simplifying the support of infrastructure features is to hide them via languages, tools, and frameworks that, whenever appropriate, transparently map invocations to remote procedure calls, assignment statements to secure database stores, loops to parallel vector operations, and so on. In Java, this may be arranged in any of several ways; for example:
No matter how it is arranged, the basic idea of transparency is to intercept code (messages, instructions) and map it to alternative code that achieves the desired semantics.
As argued especially by Kiczales [Kiczales] and Waldo et al [Waldo], transparency tends not to be a useful property of mappings to most service components. Reasons include:
It is only usually possible to program applications that work equally effectively without caring that, for example, field accesses are automatically linked to database operations. However, not knowing if or how these are performed eliminates opportunities to perform other kinds of concurrency control when necessary, to tune performance, or to undertake any other kind of application-specific refinement. In practice, the presence or absence of each quality and feature often affects high-level design and programming decisions. For example, people write distributed programs differently than they write otherwise equivalent multithreaded non-distributed programs, and write programs based on reliable multicast differently than those based on unreliable protocols. Such reliance on particular mapping decisions is hardly ever considered an asset, since it introduces context dependence to applications. However, explicit context dependence is preferable to implicit dependence.
In light of such observations and experiences, infrastructure services tend to become less transparent over time, transfering more and more responsibility for policy control to applications. Moreover, allowing explicit control often leads to entire categories of design and implementation techniques. Examples include:
| Removing transparency of | Enables development of |
| Distribution | Asynchronous protocols |
| Parallelism | Active objects |
| Database | Transactional objects |
| Location | Mobile agents |
| Callers | Authentication |
| GUI | Pluggable Toolkits |
| System services | Extensible microkernels |
| CPU Instructions | RISC |
These trends open up opportunities for developing better software. But they also open up new design and programming challenges, in particular, those that complicate the goal of providing means for scripting together components in simple ways. While they are simple at the core, flexible system architectures introduce design complexity for the sake of flexibility and extensibility.
The remainder of this paper briefly surveys some emerging design patterns seen in efforts to solve practical design problems encountered in the development of open system components. These patterns may foreshadow advances in languages, methods, and tools that attack these problems more directly. However, the main focus here is to examine existing design strategies.
Components and systems supporting flexible policies require programmatic control of the bindings linking high-level invocations to particular mechanisms. There are many roughly similar techniques for structuring services and applications to allow this. Among the best and most common is to use delegation-based approaches (most of which are variants of the Strategy design pattern[GangOfFour,Garbanito]) where:
For example, an Account deposit operation that conceptually just accepts an amount to add to a current balance might be expanded into something like:
class Account { // ...
void deposit(long amount, ...) {
authenticator.authenticate(clientID);
accessController.checkAccess(clientID, acl);
logger.logDeposit(clientID, transID, amount);
replicate.shadowDeposit(...);
db.checkpoint(this);
lock.acquire(...);
long newBalance = amount + balance;
lock.release(...);
db.commit(newBalance, ...)
UIObservers.notifyOfChange(this);
}
}
Less simple examples include methods for editing documents in groupware systems, approving claims in workflow systems, and estimating current external state in process control applications.
Delegate services need not be obtained via direct method calls;
similar issues arise using indirect invocation mechanisms such as
events [GangOfFour, JavaBeans]. The delegates themselves need not
be encapsulated as separate classes. For example, some bindings may
be to methods in the same class as the caller [Auer] and invoked via self
(this) reference, or to individual methods
(encapsulated via inner classes or reflection) or even native C
functions (as seen for example in Unix file access routines
accessed via manually created dispatch tables.)
Any of these techniques may be used, at any layer of functionality
(from the bottommost components up through end-users and system
administrators) to help ensure that consistent sets of policies are
chosen. For example, one would normally require that two
Account objects used in a scripted
transfer activity both use the same authentication
protocol, database, and so on. Ultimately, correctness relies on
appropriate component specification and documentation techniques
[D'Souza].
A few additional variants and alternatives along these lines are mentioned as they arise below. However, without too much loss of generality, subsequent examples illustrate only simple delegation-based bindings.
Invocations of flexible infrastructure operations need not lead to strictly sequential effects. Outcomes need not even have any direct bearing on the functionality of the object performing the invocation.
Nearly every such invocation serves as a gate. Gates may pass, possibly returning a value that is needed at another gate, or behave non-procedurally in either of two ways (each of which have several variants):
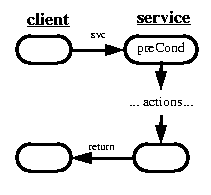
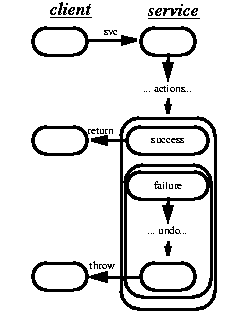
In open systems, blocking is frequently valuable at the application level, but less so at the infrastructure level [cf Greenwald]:
These concerns lead blocking protocols to be used sparingly in service components, often only for basic synchronization of memory reads and writes.
But even one kind of non-procedural outcome intrinsically adds significant complexity when nearly every invocation leads to a non-procedural potential branch in control. Without compensating effort, many branches lead to partial failures of higher level functionality.
Most design techniques address this by attempting to replace partial failures with retryable total failures, as seen in transaction frameworks, barrier synchronization algorithms, and reliable network protocols [Birman]. However, arranging for clean total failure intrinsically requires the involvement of high-level objects, thus contributing additional programmer obligations and code bloat. Additionally, while total failure is a useful goal, it is not always attainable or even desirable:
The most flexible solutions entail further parameterization, for example providing continuation callback targets for each failure condition, and, when possible, organizing handlers into larger units. However, this can make the resulting application-level code even harder to write and understand, mainly due to the need to ensure that objects maintain consistent states across each step of a multiphase action. This is difficult without the use of special development tools with syntactic support [e.g., Cardelli] for organizing this kind of event-style or state-machine processing code, where every method is split into continuations, further bloating interfaces and classes:
class App {
void mainAction(...) {
local state change;
delegate1.svc1(..)
}
void mainActionSvc1Callback(...) {
local state change;
delegate2.scv(...);
}
void mainActionSvc1FailureHandler(...) {
// ...
}
}
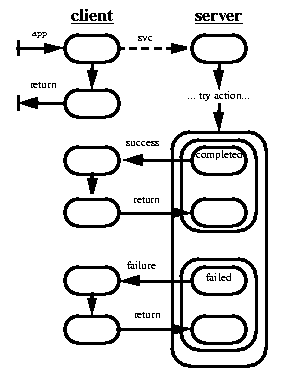
In the limit, this leads to a purely asynchronous active object programming style [Agha, Stein,OOSD,Wegner] in which every method in every object takes a form that is conceptually simple, yet not always simple to program, since support for common activities is split across possibly many methods:
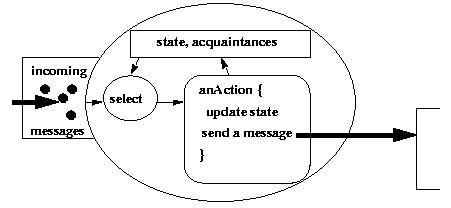
The ability to choose among and compose different sets of encapsulated services is attractive so long as there are not too many of them. However, classes such as the running Account example (especially when expanded out with exception handling) become burdensome to write: There are too many invocations, they must each use compatible policies, and they must be ordered in an appropriate manner.
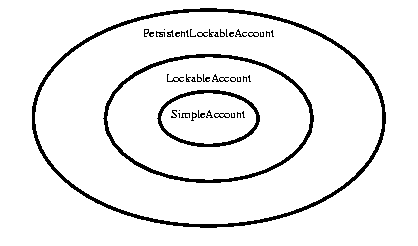
The traditional solution to such problems is bottom-up layering. For example, starting with a SimpleAccount with a deposit operation that only updates balances, you could create a LockableAccount with a deposit operation that arranges before/after [Lea] locking code via either subclassing or delegation. (Alternatively, layered metaclasses [Forman] or designs relying on internally executed Command objects [GangOfFour,Huni,Atkinson] could be used with equivalent effect.) And from there you could define for example a PersistentLockableAccount, and so on, to the point where application-level objects surround the next lower layer with only a few lines of processing.
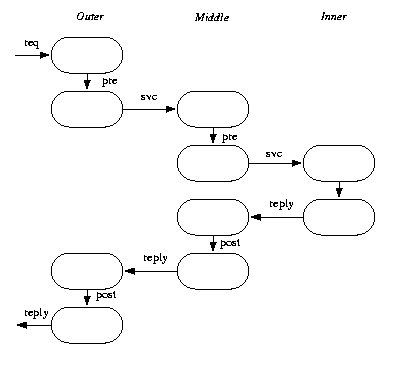
Alternatively, before/after layering may be performed dynamically by interpositioning an outer controller along a channel normally bound to an unadorned delegate. In the ideal case, each of a set of components is stackable, so can be wrapped around any other from the set in any reasonable predermined order.
These pure and simple forms of layering work well when they apply:
Typical problems encountered with layering include:
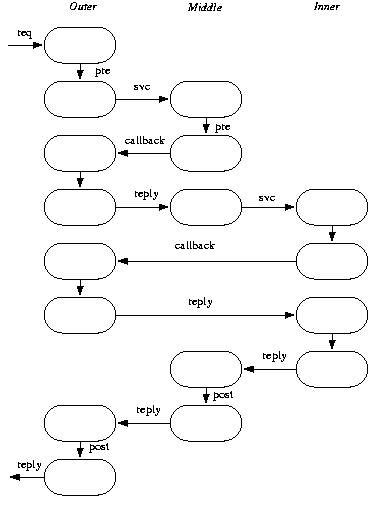
The net effect is similar to that seen when transforming exception catches to callable methods; in the limit it is nearly indistinguishable from ``open coding''. Additionally such schemes frequently obligate programmers to separate out data representations from functionality:
class State { String name; ... };
class Client {
State state;
void mainAction {
delegate1.svc(this);
}
void midSvc(Delegate d) {
saveState(...);
delegate2.svc(this);
}
// ...
}
class Delegate {
void svc(Client c) {
c.preSvc(this);
// ...
c.midSvc(this);
// ...
c.postSvc(this)
}
}
The selection of a generic set of interception (call/callback) methods, some of which might not be needed in a particular implementation, evades many problems that would otherwise occur when dealing with the different ordering demands of different policy implementations.
However, even these strategies fail to apply when there is not a defensible dominance relation between one service or set of policies and another. Program weavers introduced in Aspect-Oriented Programming [Kiczales] and related approaches [Batory] extend splicing techniques to be usable in such cases via special programming languages and tools.
Without such support, developers must provide manually woven solutions of the form illustrated in the above Account example. Such methods and classes can be hard to write. Conformance to architectural framework demands can add both lines of code and branch complexity to the task of writing semantically simple methods. Both are associated with increasing probability of making programming errors [ Humphrey]. Some of these problems appear amenable to partial solution via programming tools. The remainder of this paper focuses on issues that affect such tools, developers, or both.
There will always be things we wish to say in our programs that in all known languages can only be said poorly.-- Alan Perlis
Allocating responsibility for bindings governing the services provided within a given framework emerges as one of the most central issues in the design of components and systems. Support for various selection schemes, failure-driven control-flow decompositions, and flexible layering patterns all introduce the need to supply delegate references or specifications that add to the sets of bindings that must be transmitted to delegates.
There are many commonly used techniques for controlling bindings of families of services. Parameterization can be placed at the level of individual methods, contexts, sessions, objects, groups, classes, and programs. Each of these solutions are sometimes appropriate and useful. However, none of them appear universally applicable: Different means of selecting policies may require different points of intervention in setting consistent sets of bindings. These bindings may in turn hold over different scopes. For example, some settings may always be associated with compile-time choices, while others may not be known until, and only hold over a single service invocation.
Each method can be parameterized with control information. For example:
void deposit(long amount,
Authenticator authenticator,
Identity clientID,
AccessController accessController,
ACL acl,
TransactionID transID,
Logger logger,
FileDirectory workingDirectory, ...);
While very flexible, per-method binding requires each caller to explicitly choose parameters, thus mixing program logic with policy control. Each object along the path of some activity must deal with policy issues that it otherwise need not know about. For example, even though a deposit method need not deal directly with client IDs or working directory paths, it must relay this information to those components that do need to know. This in turn imposes the need to supply some means for clients to determine what information is needed and how to access it, yet further eroding encapsulation. Moreover, it is difficult to ensure consistency among control parameters across different objects and methods supporting a given activity.
The number of per-method control parameters can grow without bound. Adding a parameter causes code in all callers to be changed. (This can be mitigated by defining overloaded versions that omit certain parameters, instead using defaults.)
Bindings can be established globally, for example via Singletons maintaining delegates used by all objects; as in:
class Authenticator {
static Authenticator theAuthenticator();
}
class Account {
// ...
void deposit(long amount) {
Authenticator.theAuthenticator().authenticate(...);
// ...
}
}
Simpler forms of this solution are seen, for example in the Java SecurityManager. They are also seen in shell and job-control languages that bind, for example, ``physical'' files to ``logical'' channels at program start-up.
Per-program bindings rely on the intrinsic fragility and error-proneness of employing centralized global information, especially in distributed applications, and cannot support multiple concurrent policies.
Each object can maintain references to delegates as instance variables, initialized upon construction. For example:
class Account {
Authenticator authenticator;
Identity clientID;
AccessGuard accessChecker;
ACL acl;
Logger logger;
// ...
Account(Authenticator a, ...) // bind delegates
void deposit(long amount);
}
Such classes may also support tuning interfaces [Kiczales,Maeda] that rebind delegates; for example, method setAuthenticator(Authenticator a).
Per-object binding allocates responsibility for bindings to callees rather than callers. However, this may result in bindings (such as client IDs here) that may cause objects to be too narrowly specialized, and complicates efforts to transmit shared bindings down through miultlayered service components.
Also, allowing per-object bindings to vary dynamically via assignment-based tuning methods can lead to consistency errors if the object is concurrently available. The parameters in force for one activity need not hold for, and may conflict with, those for another.
There are several OO design patterns for parameterizing bindings at the class level. In languages such as C++ and Eiffel, this is usually most easily accomplished via parameterized (template) classes. In Java, the desired effects can be obtained via any of several variants of the template method subclassing pattern [GangOfFour,Lea]. Each class can contain internal ( protected) methods that return the appropriate delegate. Different parameterizations are achieved by creating subclasses that provide appropriate definitions of these methods. Among the implementation possibilities is:
abstract class AbstractAccount {
protected abstract Authenticator authenticator();
// ...
void deposit(long amount) {
authenticator().authenticate(...);
// ...
}
}
class ConcreteAccount extends AbstractAccount { // ...
static Authenticator auth;
protected Authenticator authenticator() { return auth; }
}
Alternatively, client classes can inherit from service classes. For example:
interface AccountIfc {
void deposit(long amount);
}
class Authenticated Account extends Authenticator
implements AccountIfc {
void deposit(long amount) {
this.authenticate(...);
// ...
}
}
Either way, policy control in per-class bindings becomes a compile-time decision. Objects cannot engage in multiple activities requiring different policies. Additionally, without full support for mixin inheritance [CLOS], the service subclassing approach inflexibly fixes layering order. Also, evolution of classes across time is difficult [Mezini].
Policy contexts are just maps from names to delegate bindings. Context objects are commonly seen in several guises in open OO systems; for example in registries and naming services such as Java JNDI, in CORBA Contexts that are sent as hidden parameters, property files used in X and other GUI systems, ``environment lists'' sent from shells to programs in many operating systems, and in many objects implementing the Mediator design pattern [GangOfFour]. While it is possible to support contexts as first-class language constructs [Unger,Dami,Abadi] or via tools [Smaragdakis], the effects can be obtained in Java without direct syntactic support. For example, a strongly typed version might look like:
class BankingContext {
Authenticator authenticator();
void setAuthenticator(Authenticator a);
// ...
}
class Account {
void deposit(long amount, BankingContext ctx) {
ctx.authenticator().authenticate(ctx.clientID());
// ...
}
}
Weakly-typed versions are also possible, as is per-object ownership:
class Context {
Object get(Object name);
void bind(Object name, Object val);
// ...
}
class Account {
Context currentCtx;
void deposit(long amount) {
Authenticator a = (Authenticator)(currentCtx.get("authenticator"));
a.authenticate(...)
// ...
}
}
Advantages of context-based control include:
However, there are also disadvantages:
The use of contexts and their approximations is seen in designs that provide various middle-points between the method, object, class, and program based bindings. The include state/role-basd, group-based, and session-based design patterns.
Per-object bindings may be further subdivided into per-state or per-role bindings by having objects delegate all functionality to a helper object that behaves as the main object would when it is in that state or role [GangOfFour, Fowler]. These delegates act mainly as ways to group sets of bindings so that the main object may switch among consistent sets of methods uopn switching states or roles [Abadi].
An object group is a set of objects all perhaps transiently sharing some common (often implicit) characteristics. The notion of a group extends the simple idea of membership in a collection or composite object to encompass common external access policies, common connectivity, common internal policies, and role-specific functionality [Birman,Lea]. Groups are sometimes implemented as extended forms of collections that additionally maintain and control shared context. For example, contexts may be managed as tuple spaces [Leler] such as JavaSpaces[JavaSpaces]. Alternatively, each member can individually replicate shared information when a member of a group, changing contexts when it joins and leaves different groups while assuming different roles [Strom].
Groups may also be associated with different administrative domains that immutably fix various bindings, perhaps those for entire intranet sites.
Contexts can be associated with entire activities, at least when they take the form of sessions that have well-defined starting points (and perhaps several branched end-points); for example, a user's session with a bank machine. Per-session context-based control has a diverse and spotty heritage, including:
Session-based policy control is attractive when:
One tactic for implementing session-based control in non-distributed Java programs is to extend ThreadGroups. Java ThreadGroups can represent a set of subactivities all initiated from a common ancestor. Java supplies a means for any Java code to determine the ThreadGroup it is running under. This could be exploited via code such as:
class Account { // ...
Context ctx() {
ThreadGroup g = Thread.currentThread().getThreadGroup();
return ((ExtendedThreadGroup)g).bindings();
}
}
This style of session-based contextual control appears useful enough to deserve more direct support. For example, one can imagine a language in which contextual bindings were performed implicitly via a generalization of delegation-based method lookup. (Or viewed differently, as a generalization of transaction control protocols.) However, more elaborate designs are necessary to implement session-based control in distributed settings. These may entail, for example, transfer of bindings across the steps of a mobile computation [Vitek].
Extensible parameterization of any form has an associated performance cost. However, techniques for optimizing away indirect bindings are well known, and can be applied (albeit with a sometimes massive amount of effort) whenever bindings are knowable beforehand for any given method, session, object, group, class, or program. Nearly all of these techniques are based on some form of customization: generating special versions of code by partially evaluating with respect to fixed bindings[Unger,Jones,Mosberger,Pu,Birman,Jagannathan].
Special cases include:
Tools or manual techniques for carrying these out may operate at any of the levels mentioned above for dealing with mappings. For example, Configurators [Schmidt] may be used to prearrange settings for incoming service requests, and analogs of the mechanisms that translate slow method lookups to Java quick VM instructions could be constructed at the bytecode level.